blockchain是个新造词,至少在2008年之前网上是搜索不到这个词的;
比特币的白皮书里面出现过chain of blocks的描述,但是没有直接用block chain的句子;
在早期bitcointalk.org上面的讨论中,为了方便讨论,早期参与者频繁引用chain of blocks的主题,但是谁是最早的引用者,已不可考据。
如果真正要较真blockchain这个单词第一次出现的地方,我想大概是中本聪的第一版bitcoin 源代码中;
bitcoin v0.01源代码中,中本聪第一次在函数注释中 完整的引用了block chain这个术语,鉴于中本聪在比特币白皮书发表的2年前已经开始编写源码;所以有理由确认:
- blockchain这个名词是2007-2008年间诞生于世间的
- 中本聪是比特币之父,比特币是blockchain之母
现在有一种说法,是比特币和区块链是不同的,比特币是个没有什么前途的庞氏货币,而区块链作为一种新兴的基础技术将会在很多领域发扬光大,前景光明;
对于这个说法,我认为Andreas的一场演讲值得一看:
https://www.youtube.com/watch?v=SMEOKDVXlUo
好了,八卦完毕,我们开始探究比特币里面的blockchain究竟是个什么样的技术,它是解决什么问题的,实现细节是怎样的;
然后我们一贯的风格是:光说不练假把式;在原理说明中,我们会用代码parse真正的比特币区块链文件来一探究竟。
由来
还记得我们之前的文章里面提到的,如果要建立一个分布式的账本,要解决两个问题:
- 什么样的交易是一笔合法的交易
- 哪个节点有记账的权力,如何保证整个账本是唯一且不可篡改的
我们在比特币交易的系列文章中解答了第一个问题,现在是解决第二个问题的时候了。
先思考一下货币发行的问题,比特币网络中,会有成千上万的节点参与者,哪些节点能获得发币的权利呢?或者说,凭什么这些节点能有记账权呢?
在金银货币时代,发币是通过开采金矿来实现的;采矿者承担了勘探、挖掘的风险,大家认可其开采成果并承认其铸币权;那么映射到电子世界中,能不能有一种类似的挖矿的机制呢?
中本聪的回答就是POW (proof of work–工作量证明);全网的所有节点一起算一个毫无意义的随机数字,这个数字满足以下的条件,凡是能算出这个数字的人,我们就承认他有一次的记账权:即一次铸币的权利;这个条件如下:
在一个计算周期内,计算出来的这个数字R满足 F(Chain[R]) < Target;其中F是SHA256算法,Chain是账本,Target是不断减小的,这意味着寻找R的几率会越来越小
中本聪认为算力是非常公平的、不可伪造的一种证明手段;凡是能在规定周期内正确解答谜题的人,理应获得回报;所有加入到这个比特币网络的人,都应该承认这一点,如果你不承认,那比特币网络就不欢迎你;
那么,铸币的问题解决了;但是如何防止有的节点获取记账权之后,伪造账本呢?
答案是将POW的计算结果嵌入到账本中,每一次新周期的计算,其结果必须在之前所有计算结果的基础上完成;这样如果有人想要伪造账单条账目,他就必须在一个计算周期内伪造更多的账目;如果想要伪造整个账本,就需要将比特币创世之初到现在所有的POW重新计算一遍,而能够获得这样的算力,基本上是不可能的。
那么,如何将这个计算证明过程嵌入到账本里面呢?
答案就是每个计算周期生成一个block,这个block包含了这个周期内全网的交易,而Target就嵌入到这个block中,然后将block用HASH值作为指针串联起来,构造成一条坚不可摧的chain;这就是blockchain的由来。
区块结构
如果你运行最新版本的bitcond(>=v0.16),会发现在数据目录有四类文件:
- datadir/blocks/blkxxxxx.dat: 存储原始的区块数据,这就是我们常说的blockchain数据
- datadir/blocks/index/xxxx.ldb: 区块的原始数据索引,有了它,我们就可以根据HASH值快速查找交易和区块
- datadir/chainstate/xxx:这个目录中,存放着LevelDB中的UTXO记录,以及一些这些交易来源的元数据.这些数据用来校验收到的区块和交易
- datadir/blocks/revxxxxx.dat: 在区块链分叉重组的时候需要用回滚记录去更新UTXO记录
1是原始区块数据,第2,3类数据可以从1中重建,但重建会花很长时间;在一台16Core, 32GB内存,SSD磁盘的机器上,大概要花1天左右。
第4类数据比较特殊,如果存储的数据已经落后了当前区块高度非常远的距离,其实可以删除的;但是为了保证 100%的严谨和安全,目前默认的实现还是全部保留。
3,4类数据在最初的比特币版本中,没有写入文件,就是内存里面放个MAP数据结构临时存着;后来交易量变大,多次代码重构后,变成了今天这个样子。
截至2019-01,以上数据加起来,已经超过了200GB。
那我们就主要来分析第1类数据,就是原始区块数据。
Block结构
一个block的结构异常简单,列表如下:
| Size | Field | Description |
|---|---|---|
| 4 bytes | Block Size | 当前block的大小 |
| 80 bytes | Block Header | block头信息 |
| 1-9 bytes (VarInt) | Transaction Counter | 这个block包含的交易数量 |
| Variable | Transactions | 交易 |
如果去parse blkxxxx.dat 文件,按照这个结构就能很容易拆分出每一个block;来一个工具:
https://github.com/alecalve/python-bitcoin-blockchain-parser
另外值得注意的是,因为bitcoind写入区块文件的时候是并行的,所以按照字节序解析出来的区块并不是按时间顺序排列的,blkxxxx.dat文件中,区块存储的次序是随机的;
Block Header
区块头由三组区块元数据组成。
首先是一组引用父区块哈希值的数据,这组元数据用于将该区块与区块链中前一区块相连接。就是我们前面讲的作为指针的HASH值。
第二组元数据,即难度、时间戳和nonce,与挖矿竞争相关,本质上就是前面公式里面的R值和Target值。
第三组元数据是merkle树根(一种用来有效地总结区块中所有交易的数据结构,我们在后面会介绍)。
| Size | Field | Description |
|---|---|---|
| 4 bytes | version | 当前协议版本 |
| 32 bytes | Previous Block Hash | 当前Chain上,前一个block的HASH值 |
| 32 bytes | Merkle Root | 这个block中所有交易的Merkle root key |
| 4 bytes | Timestamp | 当前block的创建时间 |
| 4 bytes | nbits | 当前block的POW难度值 |
| 4 bytes | Nonce | 这就是我们前面说的那个毫无意义的随机数,耗费巨大能源就是为了找到满足条件的Nonce |
PS:比特币客户端除了bitcoin core之外,任何团队都可以根据当前的协议开发自己的比特币软件,事实上当前也有不少其他的实现,而各个团队之间开发的不同客户端需要遵循同样的协议标准,这个协议的版本管理就是依靠开头的version字段,规则请参照BIP009
block标识符
block header中,我们有一个Previous Block Hash值,这就是我们所说的将block串联成为chain的指针。那么这个指针值是怎样计算出来的呢?
还是以创世块为例,让我们仔细研究下:
创世块的HASH值为000000000019d6689c085ae165831e934ff763ae46a2a6c172b3f1b60a8ce26f,这是一个32字节的HASH值,通过SHA256算法对区块头进行二次哈希计算而得到的数字指纹。注意,这个值仅仅是根据区块头得到的,即 SHA256(SHA256(Block Header));
仅仅依赖区块头就够了吗?是的,不要忘了,我们在区块头里面还有一个重要的HASH值,就是Merkle Tree Root Hash,Merkle Tree Root Hash标识了block中所有的交易,而Block Hash 通过HASH包含了Merkle Tree Root Hash的Block Header,唯一、明确地标识了一个区块,并且任何节点通过简单地对区块头进行哈希计算都可以独立地获取该区块哈希值。
通过Merkle Root和Block Hash决定了,一个区块被铸造出来,恶意的第三方节点是无法修改它的 (关于Merkle,请参考后面的说明);
另外需要注意的一点是: 区块哈希值实际上并不包含在区块的数据结构里,不管是该区块在网络上传输时,抑或是它作为区块链的一部分被存储在某节点的永久性存储设备上时。相反,区块哈希值是当该区块从网络被接收时由每个节点计算出来的。区块的哈希值可能会作为区块元数据的一部分被存储在一个独立的数据库表中,以便于索引和更快地从磁盘检索区块。
当我parse block得到previous block hash值时,如何去判断存在上一个真正的block呢?一般都会到索引文件里面找,就是我们前面所说的 index/xxxx.ldb文件。
区块高度
除了这个HASH值作为区块标识符,我们一般还会在区块浏览器上面看到一个说明Height;比如创世块的Height就是0;
这是程序员们按照block在chain上面的次序为block的编号,这个信息是不会写入blockchain的,只是作为区块高度在很多时候方便表示和计算;
当节点接收来自比特币网络的区块时,会动态地识别该区块在区块链里的位置(区块高度)。 区块高度也可作为元数据存储在一个索引数据库表中以便快速检索。
和区块哈希值不同的是,区块高度并不是唯一的标识符。虽然一个单一的区块总是会有一个明确的、固定的区块高度,但反过来却并不成立,一个区块高度并不总是识别一个单一的区块。两个或两个以上的区块可能有相同的区块高度,在区块链里争夺同一位置。这种情况是怎样发生的呢?
因为一个全节点会时时刻刻接收全网的区块广播,在一个生产周期内,不可避免的,会产生两个或更多的符合条件的block,这个时候会发生什么呢?
所有区块高度相同的区块会争夺成为链接上chain的权利,此时所有的矿工便会收集所有可能的chain分支,并选取最长的那一条在上面继续挖矿。
如果把这个情景图像化,我们会看到blockchain时时刻刻都处在分叉状态中,新产生的block会在chain的末尾组成多个分支,不断的消亡、新生、重组,就就好像一条末端散开的绳子有了生命一样;
关于这个情景,有个很诗意的描述词:HASH DANCE;
作为一个Geek,这真是一场让人意醉神迷的数字之舞啊。
消费 coinbase 交易需要 100 block 的成熟期,现在不少裁剪节点是以 prune 方式运行的,一般设定 prune=4096,所以说,理论上区块链重组是有可能的,但是 100 个 block,4000 个 block 级别就变成近乎不可能的事情,一般情况下,6 个 block 确认就基本上确保一切(为什么是6个确认,请参考比特币的白皮书); 历史上曾发生过最多 31 个 block 的重组事件,是在 2013 年 3 月份发生的,现在几乎不可能再有这种情况发生了;
创世区块
区块链里的第一个区块创建于2009-01-03 18:15:05 GMT,被称为创世区块(Genesis block)。它是区块链里面所有区块的共同祖先,这意味着你从任一区块,循链向后回溯,最终都将到达创世区块。
因为创世区块被编入到比特币客户端软件里,所以每一个节点都始于至少包含一个区块的区块链,这能确保创世区块不会被改变。每一个节点都“知道”创世区块的哈希值、结构、被创建的时间和里面的一个交易。因此,每个节点都把该区块作为区块链的首区块,从而构建了一个安全的、可信的区块链。
创世块比较特殊,它不是挖出来的,是中本聪手工构造的;参见这里:
https://github.com/brain-zhang/bitcoin_satoshi/blob/v0.01/main.cpp#L1439
关于创世块,之前我们提到一个有趣的事情:创世块的50BTC奖励是不能花的,这是为什么呢?
这需要我们好好研究下中本聪发布的v0.01版本的比特币源码:
https://github.com/brain-zhang/bitcoin_satoshi/tree/v0.01
- 整个比特币系统接收一笔交易的时候怎么判断其合法性呢?就是判断这笔交易的vin是否关联着一笔合法交易的vout,这些vout统称UTXO,在初版比特币里面,判断一个合法的UTXO的标准就是有没有放进区块链的索引文件中;这个索引文件和区块链文件不是一个东西,他是单独的;如果你运行初版比特币软件(v0.01);就可以看到中本聪把区块存储在blk0001.dat这样的文件里面,而把所有区块的索引存储在blkindex.dat这个文件里面;
- 那么问题就出现了,blkindex.dat 什么时机才能写入呢?通读源码发现,只有自己挖矿挖到区块,或者收到周围的广播区块的时候,才有机会写入blkindex.dat这个文件;
- 中本聪不知道有意无意,在前面手工构造创世区块的时候,没有构建索引写入blkindex.dat里面
- 后来比特币的源码不断变迁,存储UTXO的方式由BDB变成了levelDB,但是创世块一直没有没有写入到索引文件里面,这样花费创世交易的时候,没有相应的索引,创世交易的UTXO就是非法的,所以没法花费
那么如何解决呢?有两个办法:
- 就是把创世区块写到区块索引里面
- 或者在检查交易合法性的时候,单独的加一个判断条件,判断UTXO是否出自创世区块
为什么迟迟没有修正:
- 每个办法都需要一次硬分叉
- 这需要全网节点都升级这个只影响创世块的50BTC,中本聪都不在乎,何苦为了50BTC就全网升级呢?
- 最后,创世块见证着历史,其实不能花费挺好的。
coinbase
紧接着block header的,就是当前block的所有交易,其中第一笔交易就是coinbase 交易。关于coinbase交易,我们曾经在之前的文章中详细介绍过,这里就增加说明一点,coinbase交易的输出包括了所有交易的手续费,将来比特币网络的额定产出越来越少的时候,矿工们还是可以通过打包交易费用获利,来维持比特币网络的正常运转。
就当前的情况来看,再来一次减半,基本上交易费用和新区快产出就对等了。
隔离见证
实施了隔离见证之后,对于block header和coinbase都有一些变化,我们以后会详细再提。
Merkle树
区块链的数据是永不删除的,随着交易量越来越大,整个区块数据量也越来越大,那么问题又来了,不可能每个节点都下载数百GB的数据来来验证一笔交易的合法性,而作为一个分布式系统,我们是不能信赖任何中心节点的!我们怎样在一个手机钱包软件里面验证一笔交易呢?
答案是一个绝妙的数据结构: Merkle;
将比特币系统的交易和区块用Merkle树组织起来,会获得一项不可思议的能力,即使整个区块达到数百GB,每个轻节点只需要接收少许数据(MB级别),就可以完成交易的合法性校验,并且无需任何中心化的节点。
初次接触到Merlke树算法的时候,我觉得这简直是为比特币系统量身定做的,我觉得这是整个系统里面最优美、最简单、最不可思议的算法。
这是怎么做到的呢?呵呵,偶很懒,自己去翻参考资料吧。
https://en.wikipedia.org/wiki/Merkle_tree
挖矿
内容引用自: https://www.8btc.com/article/108894
有了Merkle Tree这个数据结构之后,我们非常简单的就可以用一个root hash值来唯一的确定一个block中的所有交易及排列次序;所以要证明这个block中的交易没有被篡改,只要一个Merkle Tree Root Hash值就可以了;将这个值嵌入区块头,然后对整个区块头做HASH,这个过程一旦确定,基本上就不可逆了。
那么终于到了我们前面提到的第二个问题,也是整个系统中最重要的问题:
- 哪个节点有记账的权力,如何保证整个账本是唯一且不可篡改的
这个问题的回答就是POW挖矿;大众喜闻乐见的一种行为;虽然挖矿的原理简单的不可思议,但是我觉得真正去花时间搞明白的人也没有几个;那么,我们简单说说吧:
毫无意义的随机数字
是的,朋友们,比特币本身是一个荒谬的东西,其中挖矿这种行为,更是荒谬中的荒谬:浪费一个小型国家的能源消耗,只为了计算一个毫无意义的随机数字,人类的荒谬性在此暴露无遗!好一场荒诞派戏剧 !!所有的Bitoiners其实正参演着一场现代版的《等待戈多》!!!
那么,让我们来看看,Nerd们在追求的这个毫无意义的随机数字究竟是什么吧。
再回忆一下我们前面提到的block header里面的所有字段:
| 长度 | 字段名 | 作用 |
|---|---|---|
| 4 bytes | version | 当前协议版本 |
| 32 bytes | Previous Block Hash | 当前Chain上,前一个block的HASH值 |
| 32 bytes | Merkle Root | 这个block中所有交易的Merkle root key |
| 4 bytes | Timestamp | 当前block的创建时间 |
| 4 bytes | nBits | 当前block的POW难度值 |
| 4 bytes | Nonce | 这就是我们前面说的那个毫无意义的随机数,耗费巨大能源就是为了找到满足条件的Nonce |
其中,矿工们能自由更改的:
- 32 bytes的
Merkel Root Hash值,这个可以通过调整交易的次序和block包括哪些交易来进行,但是每次调整需要一些计算 - 4 bytes的Timestamp,调整范围大概在一个比特币的生产周期内(10分钟左右),这个调整的空间很小
- Nonce,就是这个;中本聪初版发布时,其挖矿活动就是计算Nonce
- 那么算出来的Nonce需要达到什么条件呢?
1
| |
其中,SHA256(SHA256(Blockherder))就是挖矿结果,F(nBits)是难度对应的目标值,两者都是256位,都当成大整数处理,直接对比大小以判断是否符合难度要求。
为了节约区块链存储空间,将256位的目标值通过一定变换无损压缩保存在32位的nBits字段里。具体变换方法为拆分利用nBits的4个字节,第1个字节代表右移的位数,用V1表示,后3个字节记录值,用V3表示,则有:
F(nBits)=V3 * 2^(8*(V1-3) )
此外难度有最低限制,也就是说 F(nBits) 有个最大值,比特币最低难度取值nBits=0x1d00ffff,对应的最大目标值为:0x00000000FFFF0000000000000000000000000000000000000000000000000000
因此挖矿可以形象的类比抛硬币,好比有256枚硬币,给定编号1,2,3……256,每进行一次Hash运算,就像抛一次硬币,256枚硬币同时抛出,落地后要求编号前n的所有硬币全部正面向上。
这里的详细计算可以参考我们之前的一篇文章
CPU挖矿时代
在Bitcoin早期,只有少数的几个Geek来尝试运行软件,此时的bitcoin core客户端集合了钱包、全节点、挖矿的所有功能;所以早期的节点挖矿过程非常简单:
构造区块,初始化区块头各个字段,计算Hash并验证区块,不合格则nNonce自增,再计算并验证,如此往复。在CPU挖矿时代,nNonce提供的4字节搜索空间完全够用(4字节即4G种可能,单核CPU运算Double SHA256算力一般是2M左右),其实nNonce只遍历完两个字节就返回去重构块
GPU挖矿时代
很快,大家就发现挖矿这个行为只需要在一个block周期内定时获取区块头就可以,不需要每个矿机都运行一个全节点。于是最初的bitcoin软件支持了getwork 协议。
getwork协议代表了GPU挖矿时代,需求主要源于挖矿程序与节点客户端分离,区块链数据与挖矿部件分离。其核心设计思路是:
由节点客户端构造区块,然后将区块头数据交给外部挖矿程序,挖矿程序遍历nNonce进行挖矿,验证合格后交付回给节点客户端,节点客户端验证合格后广播到全网。
如前所述,区块头共80个字节,由于没有区块链数据和待确认交易池,nVersion,hashPrevBlock,nBits和hashMerkleRoot这4个字段共72个字节必须由节点客户端提供。挖矿程序主要是递增遍历nNonce,必要时候可以微调nTime字段。
对于显卡GPU来说,其实不用担心nNonce的4字节搜索空间不足,而且挖矿程序从节点客户端那里拿到一份数据后,不应该埋头工作太久,不然很有可能这个块已经被其他人挖到,继续挖只能做无用功,对于比特币来说,虽然设计为每10分钟一个区块,良好的策略也应该在秒级内重新向节点申请新的挖矿数据。对于显卡来说,运行SHA256D算力一般介于200M~1G,nNonce提供4G搜索空间,也就是说再好的显卡也能支撑4秒左右,调整一次nTime,又可以再挖4秒,这个时间绰绰有余。
节点提供RPC接口getwork,该接口有一个可选参数,如果不带参数,就是申请挖矿数据,如果带一个参数,就是提交挖到的块数据。
我们先想一下,如果要挖矿,getwork返回的最小数据是哪些呢?
只需要区块头的前76个字节就可以! 通过nNonce和nTime,就能直接构造。
但是getwork协议充分考虑各种情况,尽量帮助外部挖矿程序做力所能及的事,提供了一些额外字段。getwork的全部返字段如下:
- Data字段
共128字节(80区块头字节 + 48补全字节),因为SHA256将输入数据切分成固定长度的分片处理,每个切片64字节,输入总长度必须是64字节的整数倍,输入长度一般不符合要求,则根据一定规则在元数据末端补全数据。
- Target字段
即当前区块难度目标值,采用小头字节序,需要翻转才能使用。这其实是根据区块头的nBits计算出来的, getwork送佛送到西,直接帮你算好了。
- Midstate字段
SHA256对输入数据分片处理,矿工拿到data数据后,第一个分片(头64字节)是固定不变的,midstate就是第一个分片的计算结果,节点帮忙计算出来了。 因此,在midstate字段辅助下,外部挖矿程序甚至只需要44字节数据就可以正常挖矿:32字节midstate + 第一个切片余下的12(76-64)字节数据。
- Hash1字段
比特币挖矿每次都需要连续执行两次SHA256,第一次执行结果32字节,需要再补充32字节数据凑足64字节作为第二次执行SHA256的输入。hash1就是补全数据,同理,hash1也是固定不变的。
外部挖矿程序挖到合格区块后再次调用getwork接口将修改过的data字段提交给节点客户端。节点客户端要求返回的数据也必须是128字节。
每次有外部无参调用一次getwork时,节点客户端构造一个新区块,在返回数据前,都要把新区块完整保存在内存,并用hashMerkleRoot作为唯一标识符,节点使用一个Map来存放所有构造的区块,当下一个块已经被其他人挖到时,立即清空Map。
getwork收到一个参数后,首先从参数提取hashMerkleRoot,在Map中找出之前保存的区块,接着从参数中提取nNonce和nTime填充到区块的对应字段,就可以验证区块了,如果难度符合要求,说明挖到了一个块,节点将其广播到全网。
getwork协议是最早版本挖矿协议,实现了节点和挖矿分离,经典的GPU挖矿驱动cgminer和sgminer,以及cpuminer都是使用getwork协议进行挖矿。getwork + cgminer一直是非常经典的配合,曾经很多新算法推出时,都快速被移植到cgminer。即便现在,除了BTC和LTC,其他众多竞争币都还在使用getwork协议进行挖矿。矿机出现之后,挖矿速度得到极大提高,当前比特币矿机算力已经达到10T/秒级别。而getwork只给外部挖矿程序提供32字节共4G的搜索空间,如果继续使用getwork协议,矿机需要频繁调用RPC接口,这显然不可行。如今BTC和LTC节点都已经禁用getwork协议,转向更新更高效的getblocktemplate协议。
GETBLOCKTEMPLATE
getblocktemplate协议诞生于2012年中,此时矿池已经出现。矿池采用getblocktemplate协议与节点客户端交互,采用stratum协议与矿工交互,这是最典型的矿池搭建模式。
与getwork相比,getblocktemplate协议最大的不同点是:getblocktemplate协议让矿工自行构造区块。如此一来,节点和挖矿完全分离。对于getwork来说,区块链是黑暗的,getwork对区块链一无所知,他只知道修改data字段的4个字节。对于getblocktemplate来说,整个区块链是透明的,getblocktemplate掌握区块链上与挖矿有关的所有信息,包括待确认交易池,getblocktemplate可以自己选择包含进区块的交易。
getblocktemplate 在被开发出来后并非一成不变,在随后发行的各个版本客户端都有所升级改动,主要是增添一些字段,不过核心理念和核心字段不变。目前比特币客户端返回数据如下,考虑到篇幅限制,交易字段(transactions)只保留了一笔交易数据,其实根据当前实际情况,待确认交易池实时有上万笔交易,目前区块基本都是塞满的(1M容量限制),加上额外信息,因此每次调用getblocktemplate基本都有1.5M左右返回数据,相对于getwork的几百个字节而言,不可同日而语。
来简单分析一下其中几个核心字段, Version,Previousblockhash,Bits这三个字段分别指区块版本号,前一个区块Hash,难度,矿工可以直接将数值填充区块头对应字段。
Transactions,交易集合,不但给了每一笔交易的16进制数据,同时给了hash,交易费等信息。 Coinbaseaux,如果有想要写入区块链的信息,放在这个字段,类似中本聪的创世块宣言。 Coinbasevalue,挖下一个块的最大收益值,包括发行新币和交易手续费,如果矿工包含Transactions字段的所有交易,可以直接使用该值作为coinbase输出。 Target,区块难度目标值。 Mintime,指下一个区块时间戳最小值,Curtime指当前时间,这两个时间作为矿工调节nTime字段参考。 Height,下一个区块难度,目前协议规定要将这个值写入coinbase的指定位置。
矿工拿到这些数据之后,挖矿步骤如下:
构建coinbase交易,涉及到字段包括Coinbaseaux,Coinbasevalue,Transactions,Height等,当然最重要的是要指定一个收益地址。 构建hashMerkleRoot,将coinbase放在transactions字段包含的交易列表之前,然后对相邻交易两两进行SHA256D运算,最终可以构造交易的Merkle树。由于coinbase有很多字节可供矿工随意发挥,此外交易列表也可随意调换顺序或者增删,因而hashMerkleRoot值空间几乎可以认为是无限的。其实getblocktemplate协议设计的主要目标就是让矿工获得这个巨大的搜索空间。
构建区块头,利用Version,Previousblockhash,Bits以及Curtime分别填充区块头对应字段,nNonce字段可默认置0。
挖矿,矿工可在由nNonce,nTime,hashMerkleRoot提供的搜索空间里设计自己的挖矿策略。 上交数据,当矿工挖到一个块后当立即使用submitblock接口将区块完整数据提交给节点客户端,由节点客户端验证并广播。
需要注意的是,与上文提到的GPU采用getwork挖矿一样,虽然getblocktemplate给矿工提供了巨大搜索空间,但矿工不应对一份请求数据挖矿太久,而应循环适时向节点索要最新区块和最新交易信息,以提高挖矿收益。
矿池
在很长一段时期内,大家都是各自为战;但随着全网难度上升,个人挖矿的成功率越来越低,很可能挖数年都不能爆一个块。于是有人提出了大家合作挖矿的办法。矿池挖矿时代来临了。
矿池的核心工作是给矿工分配任务,统计工作量并分发收益。矿池将区块难度分成很多难度更小的任务下发给矿工计算,矿工完成一个任务后将工作量提交给矿池,叫提交一个share。假如全网区块难度要求Hash运算结果的前70个比特位都是0,那么矿池给矿工分配的任务可能只要求前30位是0(根据矿工算力调节),矿工完成指定难度任务后上交share,矿池再检测在满足前30位为0的基础上,看看是否碰巧前70位都是0。
矿池会根据每个矿工的算力情况分配不同难度的任务,矿池是如何判断矿工算力大小以分配合适的任务难度呢?调节思路和比特币区块难度一样,矿池需要借助矿工的share率,矿池希望给每个矿工分配的任务都足够让矿工运算一定时间,比如说1秒,如果矿工在一秒之内完成了几次任务,说明矿池当前给到的难度低了,需要调高,反之。如此下来,经过一段时间调节,矿池能给矿工分配合理难度,并计算出矿工的算力。
STRATUM
矿池通过getblocktemplate协议与网络节点交互,以获得区块链的最新信息,通过stratum协议与矿工交互。此外,为了让之前用getwork协议挖矿的软件也可以连接到矿池挖矿,矿池一般也支持getwork协议,通过阶层挖矿代理机制实现(Stratum mining proxy)。须知在矿池刚出现时,显卡挖矿还是主力,getwork用起来非常方便,另外早期的FPGA矿机有些是用getwork实现的,stratum与矿池采用TCP方式通信,数据使用JSON封装格式。
先来说一下getblocktemplate遗留下来的几个问题:
矿工驱动:在getblocktemplate协议里,依然是由矿工主动通过HTTP方式调用RPC接口向节点申请挖矿数据,这就意味着,网络最新区块的变动无法及时告知矿工,造成算力损失。
数据负载:如上所述,如今正常的一次getblocktemplate调用节点都会反馈回1.5M左右的数据,其中主要数据是交易列表,矿工与矿池需频繁交互数据,显然不能每次分配工作都要给矿工附带那么多信息。再者巨大的内存需求将大大影响矿机性能,增加成本。
Stratum协议彻底解决了以上问题。
Stratum协议采用主动分配任务的方式,也就是说,矿池任何时候都可以给矿工指派新任务,对于矿工来说,如果收到矿池指派的新任务,应立即无条件转向新任务;矿工也可以主动跟矿池申请新任务。
现在最核心的问题是如何让矿工获得更大的搜索空间,如果参照getwork协议,仅仅给矿工可以改变nNonce和nTime字段,则交互的数据量很少,但这点搜索空间肯定是不够的。想增加搜索空间,只能在hashMerkleroot下功夫,如果让矿工自己构造coinbase,那么搜索空间的问题将迎刃而解,但代价是必要要把区块包含的所有交易都交给矿工,矿工才能构造交易列表的Merkleroot,这对于矿工来说压力更大,对于矿池带宽要求也更高。
Stratum协议巧妙解决了这个问题,成功实现既可以给矿工增加足够的搜索空间,又只需要交互很少的数据量,这也是Stratum协议最具创新的地方。
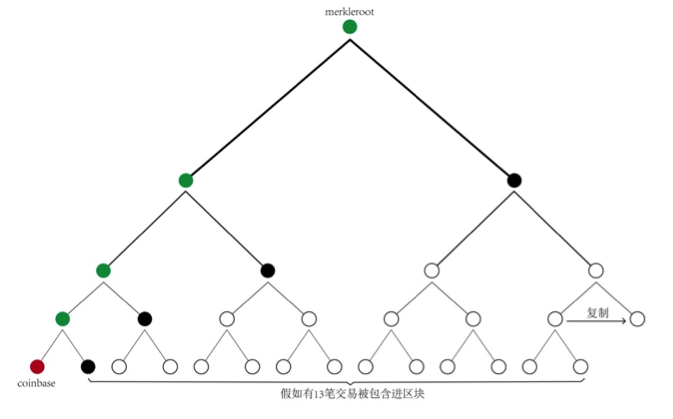
再来回顾一下区块头的6个字段80字节,这个很关键,nVersion,nBits,hashPrevBlock这3个字段是固定的,nNonce,nTime这两个字段是矿工现在就可以改变的。增加搜索空间只能从hashMerkleroot下手,这个绕不过去。Stratum协议让矿工自己构造coinbase交易,coinbase的scriptSig字段有很多字节可以让矿工自由填充,而coinbase的改动意味着hashMerkleroot的改变。从coinbase构造hashMerkleroot无需全部交易,如上图所示,假如区块将包含13笔交易,矿池先对这13笔交易进行处理,最后只要把图中的4个黑点(Hash值)交付给矿工,同时将构造coinbase需要的信息交付给矿工,矿工就可以自己构造hashMerkleroot(图中的绿点都是矿工自行计算获得,两两合并Hash时,规定下一个黑点代表的hash值总是放在右边)。按照这种方式,假如区块包含N笔交易,矿池可以浓缩成log2(N)个hash值交付给矿工,这大大降低了矿池和矿工交互的数据量。
在getblocktemplate协议和Stratum协议的配合下,矿池终于进化为完全体,可以接纳近乎无限的矿工和算力,至此比特币全网算力进入了爆炸增长的时代;
最终,普通交易、conbase交易、nNonce、nTime定义了一个Block Header的 Double SHA256 值是否符合nBits代表的难度值,而这些数据的组合共同造就了一组毫无意义的随机数字;包含这组数字的block一旦产生并广播出去,就极难伪造;正是这组数字,决定了哪个节点有记账的权力,保证了整个账本是唯一且不可篡改的。
区块链接成为区块链
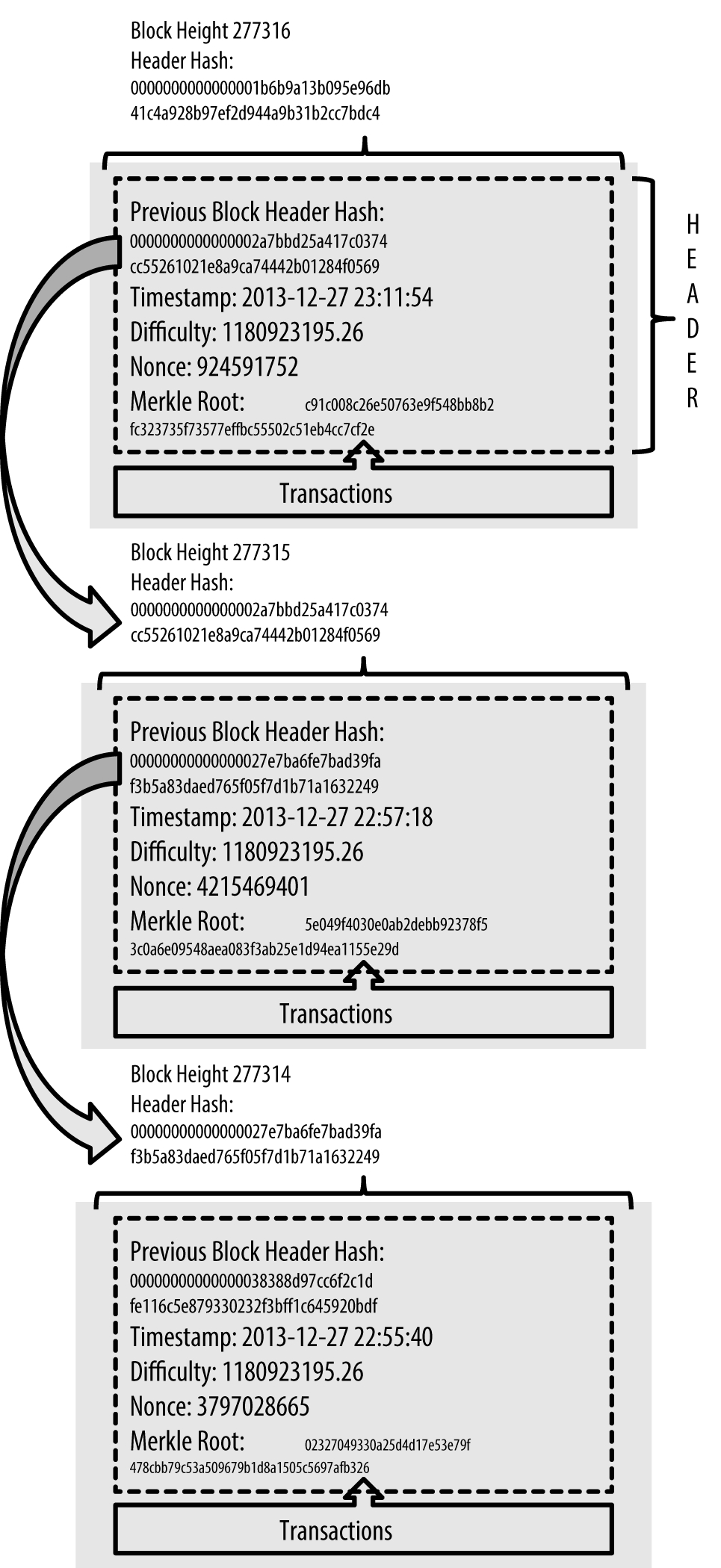
比特币的全节点在本地保存了区块链从创世区块起的完整副本。每个计算周期内矿工们辛勤的工作,会不断产生新的区块,每个区块头都用Merkle Tree Root Hash证明其包含的所有交易的不可篡改性,而区块头中的Nonce又包含着巨大的运算量来保证整个区块的不可篡改性;而区块链的本地副本会不断地更新用于扩展这个链条。当一个节点从网络接收传入的区块时,它会验证这些区块,然后链接到现有的区块链上。
最后,整条链凝结了全网矿工从比特币诞生以来的所有算力总和,这些巨大的算力保证了再伪造同样的一条链是近乎不能完成的任务。
此时整个账本是唯一且不可篡改的。
最后所有区块组成了blockchain:
SPV(简单支付)
Merkle树被SPV节点广泛使用。SPV节点不保存所有交易也不会下载整个区块,仅仅保存区块头。它们使用认证路径或者Merkle路径来验证交易存在于区块中,而不必下载区块中所有交易。
例如,一个SPV节点想知道它钱包中某个比特币地址即将到达的支付。该节点会在节点间的通信链接上建立起bloom过滤器,限制只接受含有目标比特币地址的交易。当节点探测到某交易符合bloom过滤器,它将以Merkleblock消息的形式发送该区块。Merkleblock消息包含区块头和一条连接目标交易与Merkle根的Merkle路径。SPV节点能够使用该路径找到与该交易相关的区块,进而验证对应区块中该交易的有无。SPV节点同时也使用区块头去关联区块和区块链中的其余区块。这两种关联,交易与区块、区块和区块链,就可以证明交易存在于区块链。简而言之,SPV节点会收到少于1KB的有关区块头和Merkle路径的数据,其数据量比一个完整的区块(目前大约有1MB)少了一千多倍。
小结
blockchain作为比特币的基本技术支撑之一,毫无疑问是一项前无古人的真正创新;这项技术怎么高估都不过分,我认为数十年后,可能会作为一种工业革命的基础技术跟蒸汽机、电力应用、信息技术相提并论;
比特币的链为我们提供了两项能力:
- 不可伪造的电子时间戳证明;任何依赖于有序时间的处理程序(博彩、公证、法律等等)都可以上链
- 提供了一个构造发行自定义资产(证券、股票)的基础手段,货币只是一个基本应用,任何人都可以以比特币主链为基础,构造一条侧链,并在其之上实现自己的资产发行、定价、转移功能
在未来的世界里,关于这方面的应用和创新简直层出不穷,例如预言机的实现,微支付通道,原子交换等等;我所读过的最好的关于blockchain的一些设想是这个:
https://medium.com/@creole
好啦,为了能在未来的世界里面不落人后,我们要继续学习,等我们之后的文章吧。